Me ha gustado mucho este vídeo que forma parte de la información suplementaria de un artículo publicado en Science que ha observado experimentalmente cómo se produce, durante la mitosis, el plegamiento de la cromatina nuclear y cómo se forman los cromosomas metafásicos mitóticos. Espero que lo disfrutes como yo. El artículo técnico es Natalia Naumova et al., «Organization of the Mitotic Chromosome,» Science, AOP 07 Nov 2013 [DOI].
Una de las grandes noticias científicas de 2012 fue la publicación de los resultados del proyecto ENCODE (ENCyclopedia Of DNA Elements), que reclamaban una «función» bioquímica para gran parte del mal llamado ADN basura («junk ADN» que no «garbage ADN»). Este resultado requería una revisión de ciertos aspectos de la teoría evolutiva y la genética, por lo que causó un gran enfrentamiento entre los expertos. Se han escritos muchos artículos en contra de la posible «función» del ADN basura, pero el definitivo es Dan Graur et al, «On the immortality of television sets: “function” in the human genome according to the evolution-free gospel of ENCODE,» Genome Biology and Evolution, AOP February 20, 2013 [copia gratis]. Me he enterado vía Robin McKie, «Scientists attacked over claim that ‘junk DNA’ is vital to life. Rivals accuse team of knowing nothing about evolutionary biology,» The Guardian, 24 Feb 2013, por lo que he buscado con urgencia a PaleoFreak (gran crítico de ENCODE en Twitter) y me he encontrado con un aplastante y demoledor «Golpe final al ENCODE (y viva el ADN basura),» 21 Febrero, 2013. Recomiendo su lectura, «no exenta de ironía y cierta crueldad.»
El nuevo artículo es contundente. El Consorcio ENCODE ha caído en una falacias lógica llamada afirmar el consecuente: Si A→B, y se da B, entonces se da A (lo correcto es el modus ponens: Si A→B, y se da A, entonces se da B). En concreto, los trozos de ADN que muestran una función biológica suelen mostrar ciertas propiedades, como se han observado trozos de ADN con las mismas propiedades, entonces dichos trozos de ADN tienen una función biológica (donde A=función y B=propiedad). Por ello, el Consorcio ENCODE ha publicado que más del 80% del genoma humano es funcional, es decir, que casi todos los nucleótidos tienen una función y que estas funciones se conservan evolutivamente sin sufrir selección. Todo indica que el proyecto ENCODE abusa del concepto «función» olvidando el último siglo de genética, que ha demostrado que sólo el 10% del genoma humano se ha conservado evolutivamente gracias a la selección; si fuera cierta la afirmación de ENCODE, el 70% del genoma humano sería invulnerable a mutaciones perjudiciales (un sinsentido en genética y teoría evolutiva). ENCODE ha caído también en la trampa de la apofenia, consistente en ver patrones y conexiones entre sucesos y datos aleatorios. Para ello han utilizado métodos experimentales que sobreestiman de forma consistente la posible «funcionalidad» de cada nucleótido.
En biología se pueden usar dos significados diferentes para la palabra «función» que no hay que confundir. Por un lado, la función seleccionada («selected effect» en el artículo de Graur et al.) que es resultado de la selección natural y se ha conservado porque permite al ser vivo estar mejor adaptado a su entorno. Y por otro lado, la función circunstancial («causal role» en el artículo de Graur et al.) que no tiene nada que ver con la selección y la evolución (por ejemplo, la función del corazón es bombear sangre, pero también tiene otras funciones circunstanciales, como producir sonidos, incrementar el peso corporal, etc.). El proyecto ENCODE abusa del concepto de función circunstancial al afirmar que un trozo de ADN tiene «función» si (1) es transcrito, o (2) está asociado a una histona modificada, o (3) está en una zona donde la cromatina está abierta, o (4) se acopla a factores de transcripción, o (5) contiene dinucleótidos CpG metilados. Estas funciones circunstanciales no son funciones seleccionadas y por tanto no son «funciones» en un sentido biológico estricto.
Una cuestión que permea el trabajo del Consorcio ENCODE es la función que tienen los intrones. Los genes en células eucariotas están divididos en intrones y exones, los primeros tras ser transcritos a ARN son «desechados» mientras que los segundos se unen entre sí para formar las secuencias de ARN mensajero que son traducidas a proteínas en los ribosomas. Los intrones no codifican proteínas y su papel biológico no está claro, por lo que la decisión del Consorcio ENCODE de marcarlos como «funcionales» es excesiva y muy discutible. Otra cuestión importante es el papel de los transposones, trozos de ADN que pueden moverse a lo largo del ADN y que constituyen alrededor del 30% del genoma humano y alrededor del 31% del transcriptoma humano. No está claro si algunos transposones tienen una «función» biológica, pero parece claro que la mayoría son simples parásitos, parásitos de parásitos y restos de parásitos. Asignarles una función no tiene sentido biológico.
Desde un punto de vista metodológico, el proyecto ENCODE cae en graves errores. Para comprobar si algo tiene o interviene en una función hay que eliminarlo y comprobar que la función desaparece o se modifica. Cualquier otra opción es incorrecta desde un punto de vista metodológico. El consorcio ENCODE cae en este tipo de errores constantemente.
¿Ha merecido la pena el proyecto ENCODE? ¿Servirá para algo todo el dinero gastado en este proyecto? Solo el tiempo lo dirá. En ciencia, como en las batallas, el reposo del guerrero es necesario para valorar la gesta.
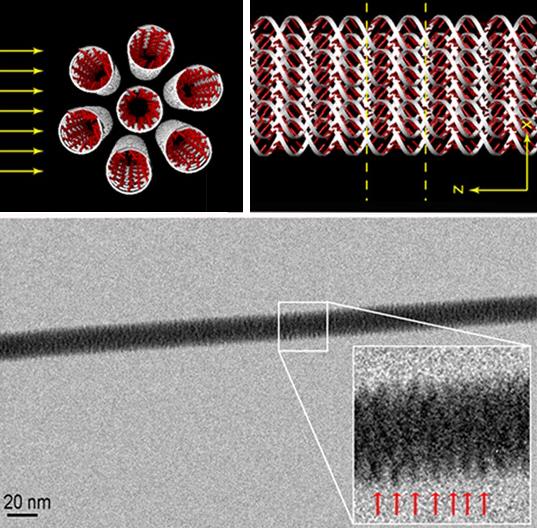
Esta fotografía obtenida con un microscopio electrónico de transmisión (TEM) muestra una fibra formada por un haz de siete moléculas de ADN en una configuración 1+6, un ADN central rodeado de 6 ADN en una distribución hexagonal; todos tienen la configuración ds ADN lineal (ds λ-DNA config. A). Para lograr esta fotografía electrónica han suspendido el haz de moléculas de ADN entre dos micropivotes de silicio y han hecho un agujero entre ellos por el que ha penetrado el haz de electrones del microscopio. Todo un alarde técnico para una foto que dejará frío a muchos, acostumbrados a ver reconstrucciones 3D de la molécula de ADN átomo a átomo. En esta fotografía la molécula de ADN se intuye (no me atrevo a decir que se ve) en los lugares donde apuntan las flechitas rojas, colocadas para ilustrar la periodicidad del enrollamiento de una de las moléculas de ADN; las flechitas rojas están separadas por 2,7 ± 0,2 nm, cada molécula de ADN enrollada tiene un diámetro de unos 8 nm y el haz 1+6 moléculas de ADN tiene unos 19 nm. El artículo técnico es Francesco Gentile et al., «Direct Imaging of DNA Fibers: The Visage of Double Helix,» Nano Letters, ASAP Nov. 22, 2012.
La noticia de la semana, la publicación de los resultados del proyecto de la Enciclopedia de Elementos de ADN (ENCODE) me ha provocado un revoltijo mental en todo lo que yo creía que sabía sobre el ADN. Ahora mismo creo que lo que llaman «ADN basura» (junk DNA) debería llamarse «ADN confuso» o «ADN desordenado» (clutter DNA); incluso, sin ánimo de resultar malsonante, yo lo llamaría «clutterfuck DNA.» Gran parte del ADN está compuesto de transposones, trozos de ADN que actúan como «virus informáticos» capaces de moverse y de copiarse a sí mismos. Gran parte de la «actividad bioquímica específica» observada por el proyecto ENCODE podría ser resultado de la actividad de estos «virus informáticos» que plagan nuestro genoma como el «spam» lo hace en nuestro correo electrónico. Te recomiendo leer Sean Eddy, «ENCODE says what?,» Cryptogenomicon, September 8th, 2012. Sobre los errores que yo mismo en este blog y gran parte de los medios hemos cometido a la hora de interpretar los resultados de ENCODE también recomiendo Mike White, «ENCODE Media FAIL (or, Where’s the Null Hypothesis?),» The Finch & Pea’s, 6 September 2012.
Todo experimento científico tiene que basarse en una hipótesis nula. Qué pasaría si se aplicara la tecnología de ENCODE a un genoma sintetizado al azar, pongamos que sea un cromosoma de unos cien millones de bases de ADN obtenido con un generador de números aleatorios. ¿Cuántos elementos de este ADN serían transcritos? ¿A cuántos de estos elementos se uniría alguna proteína? ¿Cuántos se comportarían como marcas en la cromatina? ¿Cuántas «funciones bioquímicas» en el sentido utilizado por el proyecto ENCODE serían incluidas en la «wikipedia del ADN»?
Me explico. En casa tienes dos tipos de «basura» bien diferenciadas; por un lado, ese revoltijo de objetos que una vez te fueron útiles, pero ahora no lo son, que guardas porque te traen recuerdos o simplemente por que sí; y por otro lado, las cosas que deseas desechar, que consideras desperdicios que dentro de unas horas acabarán en la bolsa de basura y en el contenedor de basura de la esquina. En ciertas ocasiones ambos tipos de «basura» se encuentran a tu alrededor, incluso pueden llegar a confundirse.
El tamaño no siempre importa, al menos respecto al ADN. Dos especies similares evolutivamente pueden tener genomas de tamaño muy diferente. La diferencia está en la cantidad de transposiciones que contienen. Los transposones, como ilustra el vídeo que abre esta entrada, son elementos o trozos de ADN que actúan como «virus informáticos» moviéndose por el resto del ADN, copiándose a sí mismos, dentro del genoma del huésped. Barbara McClintock recibió el Nobel de Fisiología o Medicina en 1983 por su descubrimiento.
Sean Eddy nos recuerda que casi el 10% del genoma humano está compuesto por casi un millón de copias del transposón Alu, que contiene unas 300 bases. Estos transposones están relacionados con ciertos virus y se cree que son parásitos del ADN. Se infiltran en el genoma, se reproducen, se multiplican, se difunden, y acaban muriendo, mutando o decayando, dejando como rastro del pasado ciertas secuencias de bases. En general, los Alu saltan de un lugar a otro dentro de la parte no codificante del ADN que podemos llamar «ADN basura» y, que se sepa, no tiene ningún efecto apreciable sobre nosotros. Algunos animales, como las salamandras, tiene su ADN repleto de transposones, por ello su longitud es unas diez mayor que la nuestra.
¿Cuánto ADN humano está anotado como transposones? Más o menos el 50%. ¿Podemos llamar a este 50% como «ADN basura»? Obviamente, tiene «funciones bioquímicas» o «actividad bioquímica específica,» pero podemos prescindir de ello sin afectar a la biología de nuestras células, por lo que podemos decir que no tiene «función biológica.» ¿Pero seguro que los transposones no tienen «función biológica» alguna? Bueno, hay excepciones que confirman la regla, pero los datos de ENCODE no permiten afirmar (al menos todavía) que así ocurra con la mayoría de ellos.
Lo que hay que tener claro es que solo el 1% del ADN codifica proteínas (son genes en sentido estricto), que entre el 1-4% no codificante actúa como regulador de la expresión de los genes, y que entre el 40-50% son transposones a los que podríamos llamar «ADN basura.» El ADN restante, entre el 40-50% todavía no se sabe muy bien qué papel juega o si tienen alguna «función» específica. El objetivo del proyecto ENCODE es aclararlo, pero los resultados publicados hasta ahora son un primer paso y no se puede afirmar que el término «función bioquímica» implica un cambio en el fenotipo o una «función biológica» en sentido estricto.
Hay una gran diferencia entre los dos tipos de «basura» que tienes en tu casa, la que acabará como desperdicio y la que atesorarás por mucho tiempo. Esta última puede que un día acabe como desperdicio, o puede que le encuentres alguna utilidad práctica. Gran parte del «ADN basura» puede ser de este segundo tipo y quizás la evolución acabe dándole una «función biológica» algún día.
El proyecto de la Enciclopedia del ADN, llamado ENCODE por Encyclopedia of DNA Elements, ha estudiado con sumo detalle el ADN humano, tanto la parte codificante (genoma), como la no codificante (mal llamada hace una década como «ADN basura»). El hallazgo más notable de este estudio es que el 80% de todo el ADN contiene elementos vinculados a funciones bioquímicas (es decir, tiene «actividad bioquímica específica»), desterrando la idea de que gran parte del ADN es simplemente «basura» evolutiva. Un resultado que fue anticipado en 2007 cuando este proyecto publicó su análisis del 1% del ADN y que obliga a redefinir el concepto de gen como unidad mínima heredada. Gran parte del ADN no codificante, que no se expresa en proteínas, tiene funciones de regulación, por lo que pueden estar relacionados con enfermedades y pueden ser dianas terapéuticas.
El ADN humano tiene unos 3.000 millones de bases («letras» A, G, T, o C), pero solo el 1% contiene unos 21.000 genes que codifican unas 90.000 proteínas. En el ADN entre los genes, el proyecto ENCODE ha descubierto unas 70.000 regiones «promotoras» que se ligan a proteínas para controlar la expresión de los genes. También ha descubierto unas 400.000 regiones «potenciadoras» que regulan (potencian o reducen) la expresión de genes, incluso de genes muy distantes entre sí. Además, ha descubierto 2,9 millones de regiones a las que se ligan proteínas (por ejemplo, factores de transcripción) en los 125 tipos de células estudiados, de las que unos dos tercios se han descubierto en un solo tipo celular y no aparecen en ningún otro tipo. De hecho, solo unas 3,700 de estas regiones son compartidas por todas las células.
En el proyecto ENCODE han trabajado unos 442 científicos durante unos 10 años, estudiando mediante 24 tipos de experimentos diferentes un pequeño trozo de ADN en 147 tipos de células humanas diferentes. El resultado se publica hoy en una serie de 30 artículos en diferentes revistas científicas, destacando 6 artículos en Nature. Nos lo cuentan Joseph R. Ecker, Wendy A. Bickmore, Inês Barroso, Jonathan K. Pritchard, Yoav Gilad, Eran Segal, «Genomics: ENCODE explained,» Nature 489: 52–55, 06 September 2012, y Ed Yong, «ENCODE: the rough guide to the human genome,» Discover Magazine, 5 Sep. 2012. El artículo técnico en Nature que describe en detalle el proyecto ENCODE es The ENCODE Project Consortium, «An integrated encyclopedia of DNA elements in the human genome,» Nature 489: 57–74, 06 September 2012. También es interesante el artículo de Ewan Birney, «The making of ENCODE: Lessons for big-data projects,» Nature 489: 49–51, 06 September 2012, del que he extraído la siguiente figura. Por cierto, en 2007 ya se publicaron conclusiones similares en Nature cuando se estudió el 1% del ADN, en concreto, en The ENCODE Project Consortium, «Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project,» Nature 447: 799-816, 14 June 2007.
GENCODE es la parte del proyecto ENCODE que está catalogando los trozos de ARN que se transcriben a partir del ADN, que constituyen casi el 75% de todo el ADN. Sus resultados exigen una nueva definición del concepto de gen. El artículo técnico es Sarah Djebali et al., «Landscape of transcription in human cells,» Nature 489: 101–108, 06 September 2012. Los sitios hipersensibles a la ADNasa I (DHSs por DNase I hypersensitive sites) son marcadores en la cromatina para la regulación del ADN, incluyendo potenciadores (enhancers), promotores, aisladores (insulators), silenciadores, regiones de control (locus control regions) y factores de transcripción. En la región del ADN estudiada se ha duplicado el número de DHSs conocidos. Los artículos técnicos son Robert E. Thurman et al., «The accessible chromatin landscape of the human genome,» Nature 489: 75–82, 06 September 2012, y Shane Neph et al., «An expansive human regulatory lexicon encoded in transcription factor footprints,» Nature 489: 83–90, 06 September 2012. La red que interconecta los factores de transcripción es estudiada en Mark B. Gerstein et al., «Architecture of the human regulatory network derived from ENCODE data,» Nature 489: 91–100, 06 September 2012. La red que conecta los genes y la parte no codificante del ADN que regula su expresión es muy compleja, contradiciendo el dogma de que la regulación de un gen se realiza mediante elementos reguladores próximos en la cadena de ADN. El artículo técnico es Amartya Sanyal et al., «The long-range interaction landscape of gene promoters,» Nature 489: 109–113, 06 September 2012.
Resumiendo mucho, lo que nos muestra el proyecto ENCODE es que el ADN y la regulación bioquímica de la célula es mucho más compleja de lo que nunca pudimos imaginar. Una de las cosas que más me interesan sobre el ADN, el estudio detallado de los aspectos dinámicos de la regulación génica, está más allá de los objetivos del proyecto ENCODE y requiere el desarrollo de nuevas tecnológicas. Serán necesarias muchas décadas para que podamos empezar a entender el funcionamiento complejo de cada célula humana a partir de su ADN y su epigenoma.
¿Qué significa que el 80% del genoma tiene una función? Que tiene actividad bioquímica específica; un elemento del ADN es «funcional» si cambia alguna propiedad bioquímica de la célula. Solo el 8% del ADN está en contacto con proteínas (como los sitios de unión a los factores de transcripción); incluso, si se incluyen los exones, este porcentaje solo sube al 9%. Por ello hay que tener cuidado a la hora de interpretar la definición de «funcional» asociada al 80% del ADN.
¿Qué significa este 80% desde el punto de vista de la evolución? Todo el ADN que sufrido el efecto de la selección en la parte más reciente de la evolución humana es considerado «funcional,» incluso si aún no sabemos si tiene efecto fenotípico o no. Solo entre el 10% y el 20% se espera que tengan dicho efecto. Dentro de la colaboración ENCODE se han tenido debates muy intensos sobre qué vocabulario utilizar. Al final la decisión de consenso que se ha tomado puede ser discutible pero está bien fundamentada en los artículos.
PS (7 sep 2012): Recomiendo ver la entrevista en vídeo a Lluís Montoliu, investigador del CNB (Centro Nacional de Biotecnología) «Cinco respuestas sobre el proyecto ENCODE y el «ADN oscuro»,» realizada por Antonio Martínez Ron @aberron y Miguel Fernández Flores para lainformacion.com.
PS (8 sep 2012): Recomiendo encarecidamente, porque me ha encantado, la lectura de la entrada de PaleoFreak, «FAQ: El Proyecto ENCODE y el supuesto fin del ADN basura,» 7 sep. 2012. En especial destaco que «¿Han dicho los científicos del ENCODE que sus hallazgos refutan la existencia del ADN basura? Creo que no, aunque no descarto que lo hayan dicho en entrevistas. Ni siquiera encuentro la palabra junk en los trabajos de libre acceso publicados en Nature.» Lo que es cierto en los seis artículos técnicos de ENCODE publicados en Nature, no así en los artículos sobre ENCODE publicados en dicha revista.
El flujo de materia oscura del halo galáctico que atraviesa la Tierra debe variar anualmente, conforme ésta gira alrededor del Sol, y también a diario, conforme ésta rota sobre su eje. Ninguno de los detectores actuales puede detectar este último efecto, ya que ninguno es direccional (aunque ha habido varios resultados controvertidos al respecto). Un físico, Katherine Freese de la Universidad de Michigan en Ann Arbor y un biólogo, George Church de la Universidad de Harvard en Cambridge, afirman en un artículo enviado a ArXiv que se puede construir un detector de materia oscura direccional utilizando ADN. Nada más y nada menos que utilizar cadenas de ADN que cuelgan de una fina lámina de oro como cortinas de cuentas de cristal. Cuando una partícula de materia oscura (sea WIMP en la figura) colisiona con un núcleo de un átomo de oro hace que éste se proyecte hacia adelante y corte las cadenas de ADN (como ilustra la figura) dejando un rastro que permite determinar con precisión la dirección de incidencia. La propuesta incluye un sistema de amplificación de las cadenas de ADN cortadas para su secuenciación con técnicas convencionales. Según los autores, este tipo de detector tendría una precisión nanométrica (el tamaño de un solo nucleótido). Sorprendente y curioso a la vez. Nos lo han contado en «Revolutionary ‘DNA Tracking Chamber’ Could Detect Dark Matter,» The Physics ArXiv Blog, July 2, 2012, haciéndose eco del artículo técnico de Andrzej Drukier, Katherine Freese, David Spergel, Charles Cantor, George Church, Takeshi Sano, «New Dark Matter Detectors using DNA for Nanometer Tracking,» ArXiv: 1206.6809, Submitted on 28 Jun 2012.
El detector debería constar de cientos (o miles) de estas hojas de oro con cadenas de ADN intercaladas entre hojas de plástico transparente, como polietileno (el PET de las botellas de agua de plástico), al igual que las hojas de un libro. Los autores estiman que sería necesario un kilogramo de oro y unos 100 gramos de ADN. Los autores opinan que este tipo de detector podría fabricarse con que las técnicas actuales, aunque hay detalles tan importantes como garantizar que no haya carbono 14 (que es radiactivo) en el ADN que no son fáciles de lograr (los autores proponen usar carbono obtenido de muestras muy antiguas y fabricar el ADN con él). En mi opinión, los problemas técnicos para la fabricación de este tipo de detectores harán que no estén disponibles en al menos una década y para entonces, yo espero que, el problema de la existencia de la materia oscura estará prácticamente resuelto.
La molécula de ADN es una de las más estudiadas, aunque aún esconde muchos secretos. Un nuevo artículo de Hashim M. Al-Hashimi (Universidad de Michigan) afirma que el 1% de los enlaces AT (entre la adenina y la timina) sufre una transición entre el modelo propuesto por Watson y Crick en 1953 y el modelo propuesto en 1963 por Hoogsteen. Se pensaba que los enlaces descubiertos por Karst Hoogsteen eran muy excepcionales y que no tenían ningún papel en la estructura de doble hélice del ADN. El grupo de Al-Hashimi ya publicó el año pasado en Nature la primera observación mediante RMN de los enlaces de Hoogsteen en moléculas de ADN, pero estimaron que su número era muy pequeño (muchísimo menos de 1%). ¿Qué función pueden tener estos emparejamientos de bases? Aún no se sabe, pero Al-Hashimi cree que podría estar relacionada con el reconocimiento molecular (cómo se acoplan ciertas moléculas al ADN o viceversa). Futuros estudios tendrán que desvelar esta función. El nuevo artículo técnico es Evgenia N. Nikolova, Federico L. Gottardo, and Hashim M. Al-Hashimi, «Probing Transient Hoogsteen Hydrogen Bonds in Canonical Duplex DNA Using NMR Relaxation Dispersion and Single-Atom Substitution,» J. Am. Chem. Soc., Article ASAP, February 6, 2012; el artículo de hace un año es Evgenia N. Nikolova, Eunae Kim, Abigail A. Wise, Patrick J. O’Brien, Ioan Andricioaei & Hashim M. Al-Hashimi, «Transient Hoogsteen base pairs in canonical duplex DNA,» Nature 470: 498–502, 24 February 2011. Me he enterado gracias a un tuit de César @EDocet que enlaza a Erika Gebel, «A Twist To DNA Base Pairing. Structural Biology: NMR spectroscopy proves the existence of an alternative to Watson-Crick base pairing,» Chemical & Engineering News, February 17, 2012. Gracias, César.
Y yo me pregunto, tendrá algo que ver esto con la conductividad eléctrica de las cadenas de ADN; ciertos estudios indican que la conducción eléctrica de ciertas secuencias de bases cambia mucho según el experimento, lo que podría estar relacionado con el hecho de que estas secuencias aparentemente idénticas en realidad no lo son porque algunas incluyen emparejamientos de Hoogsteen y otras no.
El papel de los efectos cuánticos en la química física de la vida ha sido muy discutido y criticado. La evolución podría haber cooptimizado ciertos procesos cuánticos en moléculas orgánicas. Los turcos Pusuluk y Deliduman nos proponen un modelo para la duplicación del ADN en el que los nucleótidos se comportan como cubits (bits cuánticos): (1) el reconocimiento de cada nucleótico es forzado por el entrelazamiento intrabase inducido por la superposición cuántica entre diferentes tautómeros, y (2) el emparejamiento entre nucleótidos complementarios conlleva el intercambio de entrelazamientos intrabase e interbase. Aunque la idea está todavía en pañales, es curioso hasta donde pueden llegar los físicos cuando se adentran en la biología. El único problema es que este tipo de hipótesis «arriesgadas» son casi imposibles de verificar en la actualidad. El artículo técnico es Onur Pusuluk, Cemsinan Deliduman, «Entanglement Swapping Model of DNA Replication,» ArXiv, 30 Dic. 2010.
El dogma de la biología molecular afirma que la información genética se almacena en el ADN bicatenario (dsDNA) que se divide en dos cadenas monocatenarias (ssDNA), cada una de las cuales se duplica gracias al enzima ADN polimerasa (DNApol) que toma nucleótidos del entorno y los apareja en un orden fijo (A=T, C≡G). Los detalles cuánticos de este proceso no son conocidos, debido a su complejidad, hecho que aprovechan Pusuluk y Deliduman para proponer sus ideas. ¿Hay efectos cuánticos implicados en cómo reconoce la ADN polimerasa al nucleótido que debe emparejar en la cadena de ssDNA? El proceso de replicación (o duplicación) es muy eficientie, hasta 30.000 npm (nucleótidos por minuto) en bacterias y unos 3.000 nps en humanos. Más aún, si se anulan los mecanismos de corrección de errores, se puede alcanzar un millón de npm. ¿Cómo se alcanza una eficiencia tan alta? Igual que en el caso de la fotosíntesis, lo más socorrido es recurrir a efectos cuánticos.
Todos los nucleótidos presentan formas tautoméricas alternativas, que se diferencian solo en la posición de un grupo funcional. En concreto, A, A*, T, T*, C, C*, C#, G, G* y G#. Muchas de los errores (mutaciones) en la replicación del ADN son debidos a este hecho. Por ejemplo, A* se puede aparear con C formando el enlace A*≡C, o C* se puede aparear con A formando el enlace C*=A. Pusuluk y Deliduman proponen que las formas tautoméricas de los enlaces A=T y A*=T* pueden actuar como cubits en un estado de superposición. Comprobarlo de forma experimental es muy difícil. Según los autores, la decoherencia cuántica destruye estos estados antes de que puedan ser detectados debido a la complejidad del entorno celular. Sin embargo, una molécula como la ADN polimerasa es capaz de actuar con rapidez suficiente para evitar esta decoherencia. Obviamente, una hipótesis difícil de verificar (o refutar) es lo mejor para proponer una teoría arriesgada.
¿Algún día los biólogos tendrán que estudiar en su carrera la teoría cuántica de la información?
Por cierto, la figura que abre esta entrada está extraída de J. William Bell, «Reflecting chemical intuition,» NCSA, 2008, y presenta un resultado de simulaciones cuánticas del apareamiento de dos nucléotidos obtenidas por el equipo de Todd Martinez de la Universidad de Illinois.
Esta entrada es mi primera participación para el III Carnaval de Biología organizado por Francisco Gascó, biólogo formado en la Universidad de Valencia y autor del blog El Pakozoico. Os recuerdo, si queréis participar tenéis hasta el 30 de abril para enviar vuestras entradas a Pako. El tema elegido por él son las relaciones tróficas, pero cualquier otro tema también tiene cabida. Esta entrada, por ejemplo, tiene poco de «trófica.»
Una cadena de ADN puede ser conductora, semiconductora, aislante, e incluso superconductora en función de la disposición de sus nucleótidos (pares de bases C≡G y A=T). El grupo de la doctora Jacqueline Barton publica en Nature Chemistry el nuevo récord de conducción de carga eléctrica en una cadena de ADN de 100 pares de bases (unos 34 nm de longitud) apoyada verticalmente sobre un substrato de oro. Si se cambia una sola base en esta cadena de ADN, la conducción desaparece (conduce sólo una parte de ella). ¿Por qué conduce esta secuencia de bases y no otra parecida? Nadie lo sabe. ¿Qué secuencias de nucleótidos permiten una conducción a larga distancia? Nadie lo sabe. La mayoría de las cadenas de ADN que conducen a larga distancia tienen nucleótidos colocados de forma periódica o repetitiva, pero la nueva cadena récord es aperiódica. El ADN guarda mucho más secretos que los que esconde el genoma. El artículo técnico es Jason D. Slinker, Natalie B. Muren, Sara E. Renfrew, Jacqueline K. Barton, «DNA charge transport over 34 nm,» Nature Chemistry, Published online 30 January 2011.
El ADN es una molécula compleja y llena de sorpresas. En general, el ADN es un mal conductor del calor y de la electricidad. Sin embargo, ciertas secuencias de bases conducen la electricidad durante cierta distancia. Esta conductividad del ADN depende, además de la secuencia de bases, de muchos otros factores como la longitud de la cadena, la temperatura, el grado de hidratación, etc. El mecanismo de conducción requiere una doble cadena de ADN ya que el ADN monocatenario no presenta conductividad a distancias grandes. Hasta hace poco más de un lustro, la conductividad eléctrica del ADN era difícil de medir, pero en la actualidad se han desarrollado varios dispositivos experimentales que permiten medirla con gran precisión. La doctora Barton y su grupo han fijado un mazo de cadenas de ADN de 100 nucleótidos de longitud a una placa de oro gracias a una molécula especial que actúa como ánodo; en la parte terminal de la cadena de ADN han fijado otra molécula que actúa como cátodo que emite luz cuando recibe carga eléctrica.
¿Para qué sirve descubrir secuencias de ADN que conducen la electricidad? Se cree que permitirá la fabricación de nanodispositivos electrónicos. Sin embargo, hay que recordar que sin un mecanismo de reparación adecuado, moléculas tan complejas como las cadenas de ADN largas son muy delicadas y se degradan fácilmente debido al efecto del ambiente. También se ha propuesto el uso de estas cadenas de ADN como biosensores para detectar diferentes substancias químicas.
Dos vistas 3D de la reconstrucción tridimensional del genoma de la levadura. (C) Nature
El genoma de una célula eucariota está almacenado en su núcleo dividido en cromosomas, que no están distribuidos al azar, sino que presentan una estructura tridimensional jerárquica que facilita la transcripción de ciertos genes y la replicación del genoma en su conjunto. Las relaciones espaciales y la topología de estas conformaciones cromosómicas son una de las grandes incógnitas de la biología moderna. Por primera vez se ha logrado reconstruir la conformación tridimensional completa de los cromosomas en el núcleo de una célula, en concreto, de la levadura de la cerveza (Saccharomyces cerevisiae). Como muestra la figura en 3D, la estructura es realmente sorprendente. Destaca el cromosoma XII, que adopta una topología casi inimaginable (en verde, indicada por la flecha blanca). Esta conformación parece impedir la interacción entre las secuencias de ADN de sus dos extremos. Otros cromosomas también presentan un plegamiento que podría ser responsable de ciertas interacciones intracromosómicas e intercromosómicas. Este trabajo, que se publica en Nature, nos indica que la relación entre forma y función, ampliamente documentada en proteínas, es capital también en los genomas eucariotas. Ahora sólo falta entender para qué sirve cada pliegue descubierto en este compleja estructura. Un gran reto para los próximos lustros. El artículo técnico es Zhijun Duan et al., «A three-dimensional model of the yeast genome,» Nature, Advance online publication, 2 May 2010. Los biólogos no pueden obviar la consulta de las 80 páginas de información suplementaria, donde se indica la conformación tridimensional de cada cromosoma por separado, así como su interacción topológica con sus vecinos. Los que además quieran disfrutar de la figura que abre esta entrada en 3D deberán descargar el fichero en formato PDB (Protein Data Bank) que se puede visualizar con muchos programas, como RasMol.







 El papel de los efectos cuánticos en la química física de la vida ha sido muy discutido y criticado. La evolución podría haber cooptimizado ciertos procesos cuánticos en moléculas orgánicas. Los turcos Pusuluk y Deliduman nos proponen un modelo para la duplicación del ADN en el que los nucleótidos se comportan como cubits (bits cuánticos): (1) el reconocimiento de cada nucleótico es forzado por el entrelazamiento intrabase inducido por la superposición cuántica entre diferentes tautómeros, y (2) el emparejamiento entre nucleótidos complementarios conlleva el intercambio de entrelazamientos intrabase e interbase. Aunque la idea está todavía en pañales, es curioso hasta donde pueden llegar los físicos cuando se adentran en la biología. El único problema es que este tipo de hipótesis «arriesgadas» son casi imposibles de verificar en la actualidad. El artículo técnico es Onur Pusuluk, Cemsinan Deliduman, «
El papel de los efectos cuánticos en la química física de la vida ha sido muy discutido y criticado. La evolución podría haber cooptimizado ciertos procesos cuánticos en moléculas orgánicas. Los turcos Pusuluk y Deliduman nos proponen un modelo para la duplicación del ADN en el que los nucleótidos se comportan como cubits (bits cuánticos): (1) el reconocimiento de cada nucleótico es forzado por el entrelazamiento intrabase inducido por la superposición cuántica entre diferentes tautómeros, y (2) el emparejamiento entre nucleótidos complementarios conlleva el intercambio de entrelazamientos intrabase e interbase. Aunque la idea está todavía en pañales, es curioso hasta donde pueden llegar los físicos cuando se adentran en la biología. El único problema es que este tipo de hipótesis «arriesgadas» son casi imposibles de verificar en la actualidad. El artículo técnico es Onur Pusuluk, Cemsinan Deliduman, «

